プレスリリース要約
ファインディ株式会社は、2026年10月9日にデータエンジニアリングの未来を議論する「Data Engineering Summit 2026」をリアル開催することを発表し、スポンサー募集を開始しました。AIネイティブ時代におけるデータ基盤構築と利活用の実践知が集まる場として、経営者や技術リーダーから高い注目を集めています。
本カンファレンスは「AI時代のデータ利活用と基盤構築」をテーマに、東京・八重洲にてオフライン限定で開催されます。基調講演には一般社団法人データマネジメント協会日本支部(DAMA)の木山靖史会長が登壇するほか、Databricks、Snowflake、Google Cloudといったデータ基盤大手のキーパーソンが勢揃いします。スタートアップからエンタープライズまで、データ基盤の構築や利活用を担う実務者や開発責任者が一堂に会する予定です。
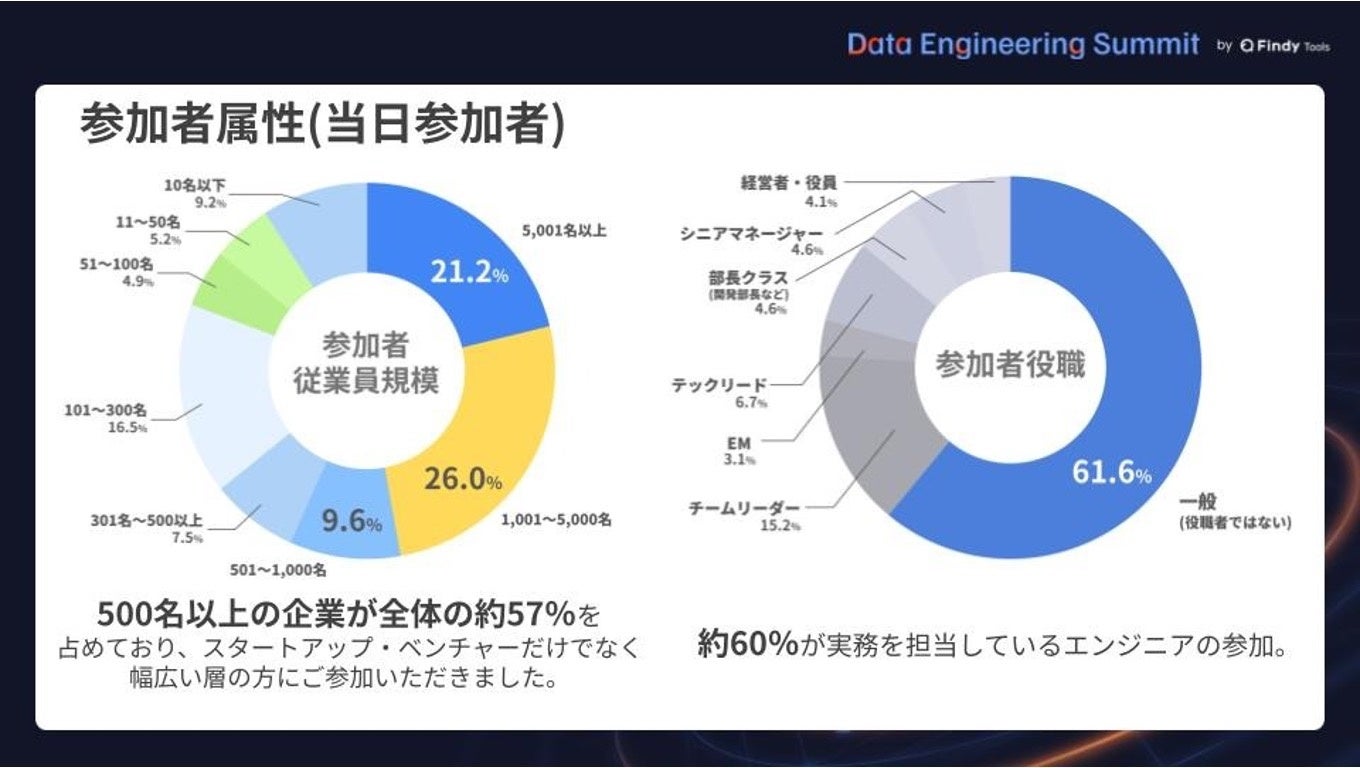
前回のオンライン開催では1,242名の申し込みを記録し、そのうち50%以上が従業員500名以上の大企業所属という実績を持ちます。今回はオフラインに特化することで、参加者同士や協賛企業とのより深いネットワーキングを促進します。スポンサープランは「Platinum」から「Exhibition」までの4種類が用意されており、リード獲得や自社の技術ブランディングに活用可能です。
Journalポイント
実はこれ、単なるエンジニア向けの技術的な勉強会ではなく、今後の企業の 競争力に直結する重要インフラ について議論する注目の場なんです。
え、そうなんですか?データエンジニアリングって、開発部門の専門職の人たちだけが関係する難しい仕事だと思っていました。
そう見えがちですが、実は多くの企業が新しい技術を導入しようとして、社内のデータが整理されておらず活用できないという壁にぶつかっているんです。
なるほど。最近よく聞く AI などを活用しようとしても、元になるデータがバラバラだと上手く動かないということですか?
AIというのは人工知能のことで、コンピュータに人間のような知的な処理を行わせる技術ですが、それを活かすためにも、まずは人間がデータを「AIが理解できる形」に整えておく必要があるんです。
なるほど!じゃあ、その「データを整える仕組み」をあらかじめ作っておけるかどうかが、企業の成長を左右するってことですね?
その通りです。前回のイベントでは 1,200名以上 の申し込みがあり、しかもその半数以上が従業員500名以上の大企業の担当者でした。それだけ多くの企業がこの課題に直面しています。
大企業ほどデータの量も多いから深刻そうですね。今回はどんな人たちが登壇してノウハウを話す予定なんですか?
今回は業界全体をリードする Databricks や Snowflake、Google Cloud といった大手3社や、データマネジメントの専門家が登壇します。
業界のトップランナーたちが集まるわけですね。自社のデータ戦略を考える上でとても参考になりそうです!