プレスリリース要約
一般財団法人GovTech東京と東京都は、行政の専門知識に特化し、高い正確性と透明性を備えた『行政特化型国産AIモデル』の共同開発に乗り出します。これに伴い、構築・実証事業を共に行う大学や研究機関の公募を開始しました。行政特化のLLM開発は、官公庁のDXや公共サービス改革の起爆剤として注目されます。
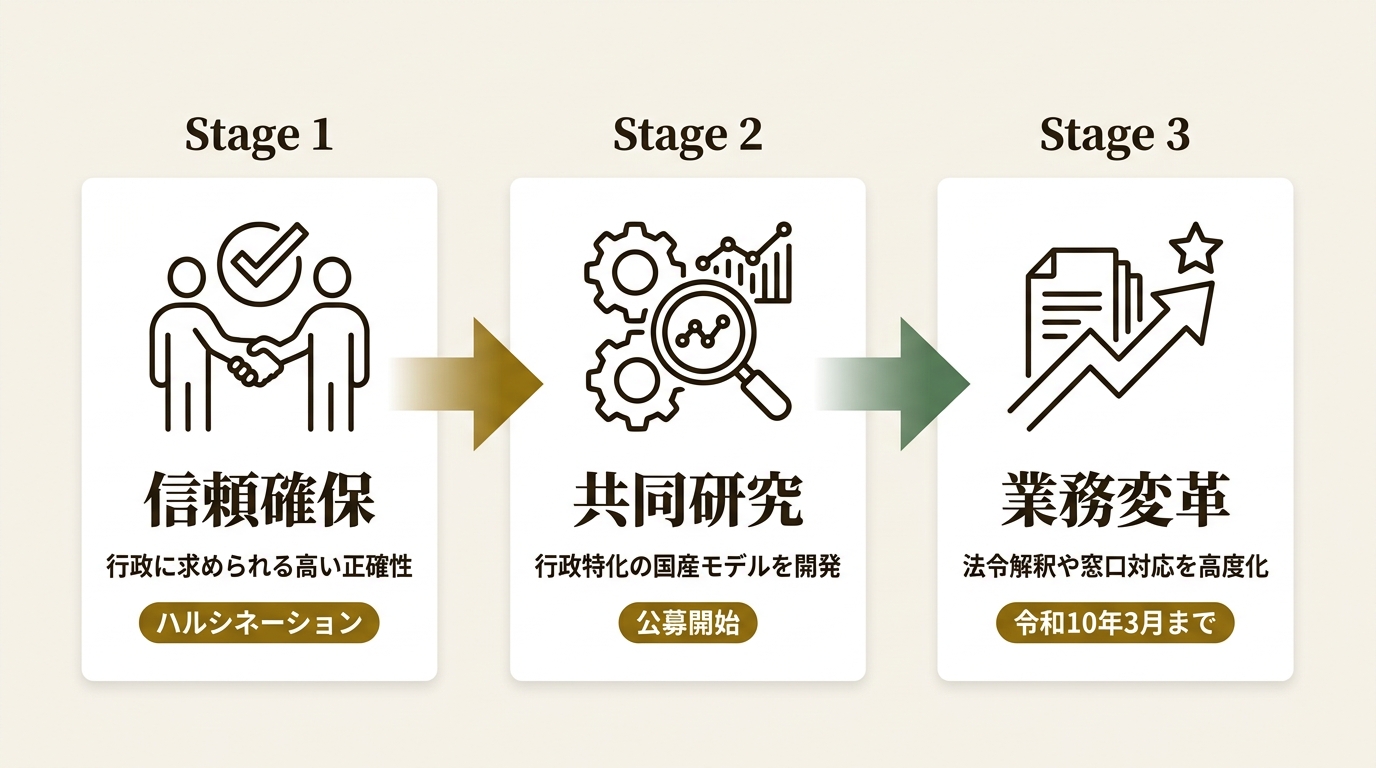
東京都とGovTech東京は、行政における生成AIの安全かつ効果的な活用を目指し、大学等の研究機関を対象とした共同研究の公募を開始しました。背景には、一般的な大規模言語モデル(LLM)を行政業務に適用した際、事実と異なる回答を生成する『ハルシネーション』が発生しやすいという課題があります。行政は都民の権利義務に直結する説明責任を負うため、回答の根拠や判断プロセスの透明性が極めて重要です。本事業では、行政特化型の国産AIモデルを構築することで、正確性と信頼性の高いシステム構築と、行政業務の大幅な効率化・支援体制の確立を目指します。
公募対象は大学、大学院、高等専門学校、またはこれらに附属する研究機関等で、最終的に1者が選定される予定です。三者(東京都、GovTech東京、採択機関)で協定を締結し、期間は令和8年7月頃から令和10年3月31日までとなっています。令和8年度の構築・実証費用として最大1億1千万円が用意され、令和9年度以降の予算は成果を踏まえて別途決定されます。GovTech東京が開発を統括し、同法人の生成AIプラットフォーム『A1(えいいち)』と連携させることで、実際の行政現場で稼働可能なシステム環境を整備していきます。
Journalポイント
実はこれ、単なるAIの導入実験ではなく、行政の信頼性を担保するための国産LLM開発プロジェクトなんです。大学の知見を集めて開発します。
え、そうなんですか?そもそもLLMという言葉もよく聞きますが、汎用的なAIでは駄目なのでしょうか?
LLMというのは大規模言語モデルのことで、文章生成を行うAIの基盤技術です。汎用的なLLMは、存在しない法律をでっち上げるハルシネーションという誤回答のリスクがあり、説明責任がある行政ではそのまま使えないという課題があるんですよ。
実用性を考えると、普通にデータベースを検索するシステムにすれば、誤回答は防げるんじゃないんですか?
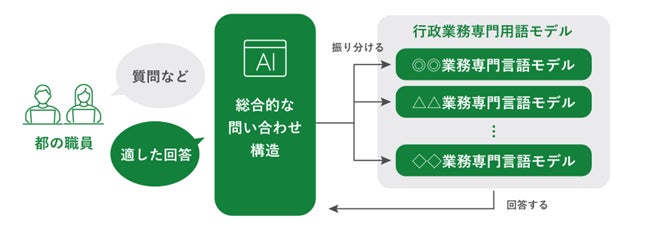
たとえば、行政文書には専門用語が多く、単なる検索では複雑な法令の解釈や文脈まで判断できません。今回のプロジェクトでは、東京都が持つ本物の行政データを活用して、正確で根拠が検証できるモデルを構築します。
なるほど!単にデータを調べるだけでなく、大学の持つAIの専門知見と、東京都の実データを掛け合わせて賢いAIを育てるのですね?
その通りです。大学などの研究機関がAIの最新知見を提供し、GovTech東京がシステム構築を統括します。予算も令和8年度だけで最大1億1千万円が用意されており、かなり本格的な体制で開発が進められます。
他の都道府県や国でも、同じように行政に特化した専用のAIを開発する動きは活発になっているのでしょうか?
実は自治体や官公庁全体で行政DXへの投資が急速に進んでいます。東京都のこの取り組みが成功すれば、全国の地方自治体が安全に使える共同プラットフォームの基盤になる可能性を秘めているんです。
行政サービスがより安全で便利になる未来がとても楽しみです。今回の取り組みの意義がよく分かりました!