プレスリリース要約
NTTは、画像と言語を扱うマルチモーダルAIの信頼性を高める新技術「根拠強化デコーディング」を確立しました。従来のAIは、提示した「推論の根拠」を無視して回答を出力する課題がありましたが、本技術は追加学習なしで根拠と回答の一貫性を保証します。ビジネスの意思決定やAI連携における信頼性向上への貢献が期待されます。
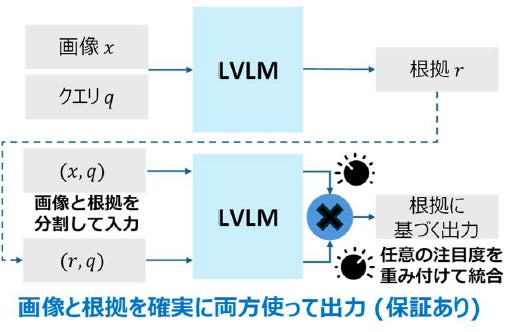
NTTが開発した「根拠強化デコーディング」は、大規模視覚言語モデル(LVLM)が段階的に思考するプロセス(CoT)において、自身が生成した推論根拠と最終的な回答が矛盾してしまう重大な課題を解決する技術です。従来のLVLMでは、推論の根拠を無視して回答を導き出す「ブラックボックス化」が起きていましたが、新技術では画像情報と根拠情報を分離して処理し、双方を最適に組み合わせて出力します。これにより、AIの回答プロセスにおける「説明可能性(XAI)」が飛躍的に向上します。
本技術の最大の特徴は、追加の訓練データやコストのかかる再学習を必要としない「プラグアンドプレイ型」の実装が可能である点です。数理的なアプローチにより、モデルが出力する確率分布(ロジット)の重み付き和を計算するだけで、既存のあらゆるLVLMに組み込むことができます。実験では、様々なモデルで推論性能(正答率)が大幅に向上したほか、より高品質な根拠を与えるほど推論精度がさらに向上することが実証されました。本成果は最難関国際会議「CVPR 2026」にて発表されます。

Journalポイント
実はこれ、AIが「もっともらしい嘘の理由」を並べて回答するのを防ぐ、極めて実用的な仕組みなんです。
え、そうなんですか?AIってちゃんと自分で考えた根拠に基づいて回答しているものだと思っていました。
実は今、マルチモーダルAIにおいて、画像と推論根拠を同時に処理すると、根拠を無視して画像だけで答えを出してしまうという課題があるんです。
でも、それってもともとAIの仕組みとして、根拠と回答がセットで学習されているんじゃないんですか?
いいえ、従来のモデルは根拠を「出力の一部」として生成するだけで、その内容に縛られる因果関係はありませんでした。そこでNTTは、画像と根拠の処理を数学的に分離して組み合わせる方法を開発したのです。
なるほど!じゃあ、この技術を既存の LVLM に導入すると、具体的にどう変わるんですか?
LVLMというのは画像とテキストを同時に理解できるAIモデルのことで、今回の技術を使えば、モデルに追加学習をさせることなく、出力のロジットを計算するだけで推論精度を大幅に高められます。
他の会社も似たようなこと、つまりAIの説明可能性を高める研究をしているんですか?
はい、業界全体で 説明可能AI への関心は非常に高まっています。しかし、その多くは膨大な再学習コストがかかるのに対し、今回の手法は追加コストがほぼゼロという点で大きな優位性があります。
なるほど、追加コストなしで信頼性が上がるなら、多くの企業が導入しやすそうですね。勉強になりました!