プレスリリース要約
Nishika株式会社は、AI音声文字起こしサービス「SecureMemo」の大規模アップデートを実施しました。日本語に特化した高速モデルの刷新や要約AIモデルの最適化により、会議のリアルタイム文字起こしと議事録作成がさらに高速化・高精度化しており、業務効率化を推進する企業から注目を集めています。
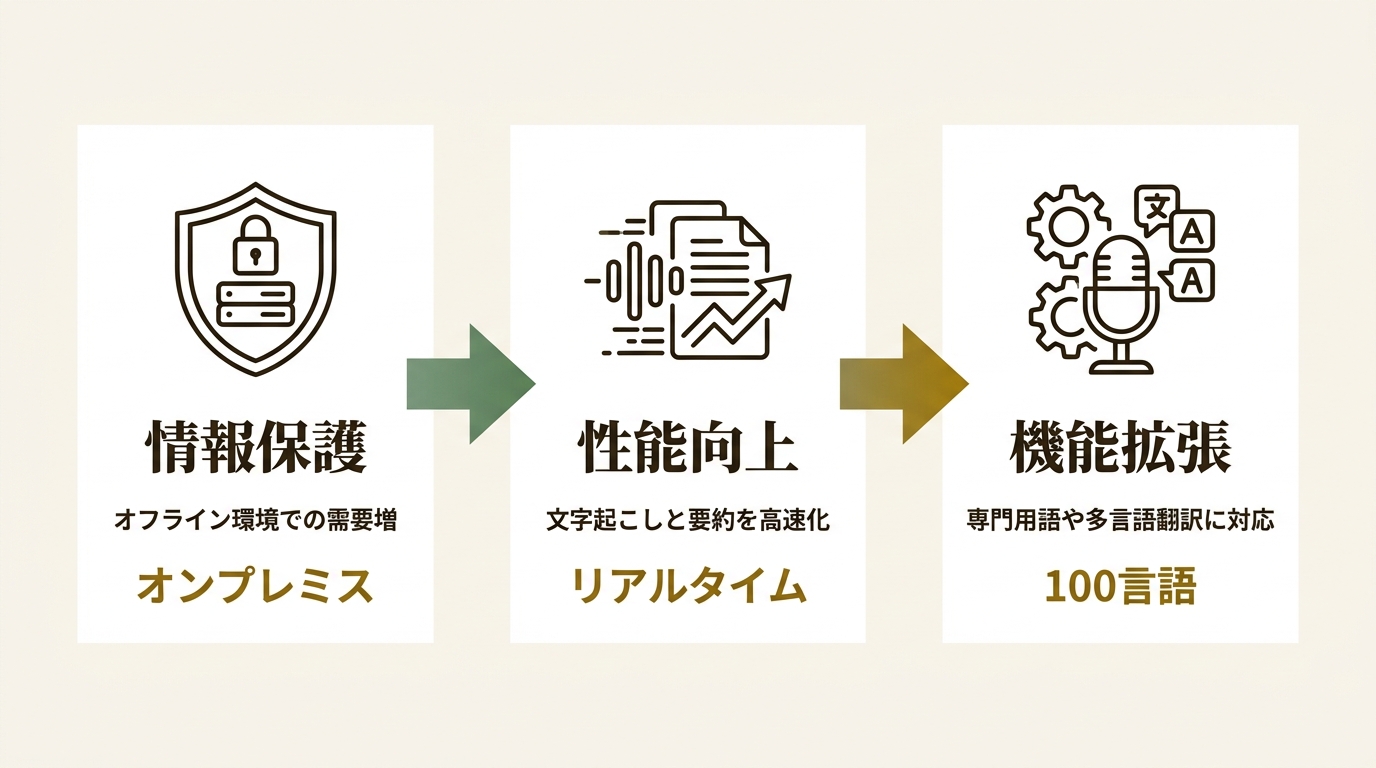
今回のアップデートでは、独自開発の音声認識AI「shirushi」シリーズが刷新されました。日本語・高速モデルの「shirushi-p」は認識精度が多言語モデルと同等レベルに向上し、リアルタイムでの応答速度も大幅に改善されています。さらに、議事録要約機能に用いる大規模言語モデル(LLM)の最適化により、従来と同等の要約品質を維持しながら、処理速度の向上とメモリ消費量の削減を実現しました。
「SecureMemo」は、外部ネットワークから遮断された環境で動作するオンプレミス型と、GPUサーバー環境で高速処理を行うクラウド型(SecureMemoCloud)の2つの形態を提供しています。独自の音声認識AIにより96.2%という高い文字起こし精度を誇り、今回のアップデートによって、長時間の会議データや大規模運用における安定性と操作性がさらに向上しました。
Journalポイント
実はこれ、セキュリティが厳しい オンプレミス環境 でも最新の生成AIによる高速な要約ができるようになったんです。
え、そうなんですか? オンプレミスってセキュリティは高いけど、システムが重くて時間がかかるイメージがありました。
オンプレミスというのは、外部のネットワークに接続せず、自社内のサーバーだけでシステムを運用する仕組みのことで、情報漏洩を防ぐのに最適です。実はこれまで、高精度な 大規模言語モデル(LLM) をローカル環境で動かすには膨大な計算資源が必要で、処理速度が課題でした。
でも、それってもともと高性能なサーバーを導入すれば解決する話じゃないんですか?
LLMというのは、大量のテキストデータを学習し、人間のような文章を生成するAIモデルのことです。確かに高性能な GPU(画像処理半導体) を積めば速くなりますが、コストが跳ね上がります。今回はAIモデル自体のアルゴリズムを改良することで、同じ設備でも劇的に処理を軽量化・高速化させたのがポイントです。
なるほど!じゃあ、コストを抑えながらも、セキュリティとスピードを両立できるってことですか?
GPUというのは、AIの高速な計算処理に特化した半導体のことです。その通りで、今回のアップデートにより、長時間の会議データでも安定して 自動要約 を生成できるようになりました。文字起こし精度も 96.2% と非常に高く、実用的な議事録がすぐに完成します。
他の会社も似たような製品を出しているのでしょうか?
クラウド型の文字起こしサービスは増えていますが、完全に オフラインの環境 で、ここまで高精度な自動要約や自動話者識別まで提供できるサービスは、国内でも非常に稀なんです。
なるほど、セキュリティに厳しい金融機関や官公庁でもこれなら導入しやすいですね。勉強になりました!